Huasheng Xiao1, Yong Gao2, Shen Li3, Xiaona Zhang1, Junsong Han1, Biaoru Li4*
1Shanghai Biotechnology Corporation, 151 Libing Road, Shanghai, 201203, P.R. China
2Department of Oncology, Shanghai East Hospital, Tongji University, 150 Jimo Road, Shanghai, China
3Department of Surgeon, University of Pitts medical School, Pitts, PA 15224, USA
4Department of Pediatrics, Division of Oncology and Hematology, MCG, Augusta, GA, USA
*Corresponding Author:
Biaoru Li
Faculty of Research Scientist and Associate Member, Clinical Bioinformatics Specialist
Pediatric Oncology and Hematology Division, Children Hospital of Georgia
Augusta, GA 30912, USA
E-mail: BLI@gru.edu
Received date: November 17, 2015; Accepted date: November 30, 2015; Published date: December 07, 2015
Citation: Xiao H, Gao Y, Li S, et al. A Case Report of Personalized Chemotherapy for Metastatic Cardiac Sarcoma. J Clin Epigenet. 2016, 1:1. DOI: 10.21767/2472-1158.100006
Copyright: © 2016 Biaoru Li, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Keywords
Gene expression signature (GES); Therapeutic targeting identification (TI); Quantitative network; Drug discovery; Betweenness centrality (BC); Degree centrality (DC)
Introduction
Personalized medicine is a new treatment model to be directly tailored for physicians to care individual patient relying on personal genomic profiles [1]. It is often called as "the right treatment for the right person at the right time." Most successful examples of personalized treatments should have a rational clinical genomic analysis [2]. Following Research and Development (R&D) of clinical genomic techniques and analysis, clinical genomic profile along with system modeling has been increasingly reported for personalized therapy since 2007 [3]. Here we introduce a case report by using clinical genomic analysis including sampling cardiac sarcoma cells and normal cells from FFPE tissues (Formalin-Fixed Paraffin-Embedded tissue), analyzing mRNA genomic expression level, discovering gene expression signature (GES) by system modeling and uncovering sensitive drugs from drug-bank for the patient suffering from metastasis of cardiac sarcoma.
Clinical genomic analyses consist of a pair of genomic data from a pair of surgical tumor tissue vs normal tissue by in vivo harvest, or from a pair of tumor cells vs. normal cells in situ harvest obtained from laser capture microscopy (LCM) or from a pair of cells by ex vivo culture from clinical specimens [4]. Here a pair of cardiac sarcoma cells vs normal cardiac cells obtained from LCM was used to genomic analysis for the clinical patient. Moreover, system modeling concerning GES has the ability to provide some information required for therapeutic targeting identification and drug discovery. After clinical genomics database were combined with quantitative bioinformatics analysis, GES genes provide us to identify therapeutic targeting and discover drugs for patients with sensitivity drugs for the tumor diseases. Here, in order to clearly introduce genomic analysis and diagnosis for personalized therapy, we present a mining process from microarray data obtained from a pair of cardiac sarcoma cell and normal cardiac cells, quantitative bioinformatics analysis for discovering GES and sensitive drug discovery for the patient application. Following the three steps, that is, mining genomic profile, discovering therapeutic targeting and uncovering sensitive drugs, finally, a list of sensitive drugs targeting cardiac sarcoma will be used for the patient personalized chemotherapy.
Clinical Specimens and Method
Patient and specimen
The patient was given diagnoses according to clinical criteria. Informed consent of the patient was obtained before tumor tissue sampling. Cardiac sarcoma cells and normal cardiac cells were obtained from laser capture microscopy. Cardiac sarcoma was diagnosed and classified according to cell type by conventional pathology.
Microarray performance
Microarray was performed to RNA sampling from the FFPE specimen, each containing triple chips for sarcoma cells and normal cardiac cells. RNA extract and microarray process were prepared according to the manufacturer instructions (Affymetrix Expression Analysis Technical Manual; Affymetrix, Santa Clara, CA) [5]. Briefly, RNA specimens from cardiac sarcoma cells and normal cardiac cells were extracted by Trizol reagent (Invitrogen, Carlsbad, CA) and cleaned by RNaeasy column (Qiagen, Valencia, CA). After sequential washing, total RNA was eluted in RNasefree water. Isolated total RNA was quantified and its integrity was confirmed on a 2100-Bioanalyzer. Each 1 ug of triple RNAs was used to prepare biotinylated antisense RNA (cRNA) using Ambion’s MessengeAmpII-Biotin Enhanced kit (Ambion, Austin, TX) and 15 ug of fragmented biotinylated cRNA was hybridized to each Genechip Human Genome U133-plus2 for the triple experiments [6].
Bioinformatics analysis
Routinely, at least three ways can be used as mining clinical genomic data for heterogeneous cells, which are hierarchical cluster, principle component analysis (PCA) and self-organizing map (SOM) [7]. In these analyses, after normalization of microarray expression data by MAS5, hierarchical clustering and significance of microarray (SAM) were used for the mining. All of hierarchical clustering and SAM are performed by BRB platform [8]. Briefly, in order to mine specific gene profile from cardiac sarcoma metastasis, we first compared triple profiles of the cardiac sarcoma cell to triple profiles of normal cardiac cells by SAM and Hierarchical clustering according to expression patterns with two fold change increase. After genomic profiles were uncovered with more than two fold increase, the profiles of patient specimens were classified as up-regulation and downregulation. 15 genes from up-regulation genes were used to sensitivity test and 15 genes from down-regulation were applied to specificity test. After sensitivity and specificity tests, we used genomic profile from up-regulating genes to mine GES genes, or called as therapeutic targeting identification (TI) in which some genes have higher linking with most or all of tumor cell function. Our quantitative analysis method (called as QM) of network topology focused on Betweenness Centrality (BC) and Degree Centrality (DC). Therapeutic identification (TI) using QM was identified by Python scripts as our previous report [9]. In order to provide correct genomic profiles based on results of specificity assay, we also used Correlation Based Method (CBM) to further mine second genomics profiles from the cardiac sarcoma cells as previous publication [10]. GES genes from up-regulating profiles from QM and CBM data for specific cardiac sarcoma are input into GeneGo software and Genebank to search drugs, a list of sensitive drugs were discovered to targeting cardiac sarcoma.
Validation of GES with their drugs for clinical application
After QM and CBM profiles with their sensitive drugs were uncovered, Q-rtPCR was further used to confirm the targeting gene expression. Moreover, drugs related with therapeutic identification genes were identified by computational mimic analysis using Python scripts [11] for specifically targeting the cardiac sarcoma cells.
Results
Patient information
The patient is 41 years old female. In July of 2012, she felt sudden chest pain and was found cardiac sarcoma located at right atrium by PET/CT. Pathological evidence reported CD34+ cell cardiac sarcoma (with CD34 cell 90%, CD99 40%, myoglobin 50%). After surgical removal of the sarcoma in July of 2012, eight months later, PET/CT reported multiple metastasis in right atrium, thoracic vertebra (6, 9) and lumber vertebra (5) and left upper humerus. A radiation therapy was selected by TOMO for 18 days. Because radiation therapy cannot control the metastasis, the patient decided to apply for personalized chemotherapy after radiation therapy 1 year later.
Microarray and genomic profile results
In order to mine gene profiles from patient specimens, we selected Affymetrix human genome U133-plus2 as chip assays including triple repeats from a pair of cells obtained from cardiac sarcoma cells and normal cardiac cells by LCM sampling from FFPE tissues. After microarray performance with triple repeat each, significant analysis of microarray (SAM) was used for mining genes as Supplement Table 1 and Figure1A, 1308 genes have up-regulation and 1935 genes have down-regulation. 15 genes from up-regulation genes (1308 genes) were used to assay sensitivity test and 15 genes from down-regulation were used to assay specificity test (1935 genes). Results demonstrated that 87% was confirmed by sensitivity test and 37.5% was illuminated by specificity test with R value 0.712 and 0.583, respectively. In specificity test group, one gene (FABP4) was failed to perform to PCR process.
| Genes |
BC (100%) |
DC |
CC |
Gene Description |
| VIM |
0.34 |
1 |
0.02 |
vimentin |
| UCP2 |
0.28 |
1 |
0.02 |
uncoupling protein 2 (mitochondrial, proton carrier) |
| GRB1 |
0.23 |
1 |
0.05 |
phosphoinositide-3-kinase, regulatory subunit 1 (alpha) |
| BRCA1 |
0.23 |
1 |
0.04 |
breast cancer 1, early onset |
| ESR1 |
0.22 |
1 |
0.04 |
estrogen receptor 1 |
| MAP3K3 |
0.17 |
1 |
0.02 |
mitogen-activated protein kinase kinasekinase 3 |
| KPNB1 |
0.14 |
1 |
0.11 |
karyopherin (importin) beta 1 |
| CPSF4 |
0.14 |
1 |
0.02 |
cleavage and polyadenylation specific factor 4, 30kDa |
| HSP |
0.14 |
1 |
0.05 |
heat shock protein 90kDa alpha (cytosolic), class A member 1 |
| CCDC85B |
0.14 |
1 |
0.01 |
coiled-coil domain containing 85B |
| UBE2I |
0.13 |
1 |
0.04 |
ubiquitin-conjugating enzyme E2I (UBC9 homolog, yeast) |
| FXR2 |
0.13 |
1 |
0.02 |
fragile X mental retardation, autosomalhomolog 2 |
| ATXN1 |
0.12 |
1 |
0.01 |
ataxin 1 |
| EWSR1 |
0.12 |
1 |
0.02 |
Ewing sarcoma breakpoint region 1 |
| HGS |
0.12 |
1 |
0.03 |
hepatocyte growth factor-regulated tyrosine kinase substrate |
| RPS27A |
0.12 |
1 |
0.34 |
ribosomal protein S27a |
| CALM1 |
0.11 |
1 |
0.01 |
calmodulin 1 (phosphorylase kinase, delta) |
| HSPA8 |
0.1 |
1 |
0.05 |
heat shock 70kDa protein 8 |
| TBP |
0.1 |
1 |
0.1 |
TATA box binding protein |
BC means “Betweenness Centrality”, DC indicates “Degree Centrality” and CC is “Clustering coefficient”.
Table 1: Result of quantitative network analysis.
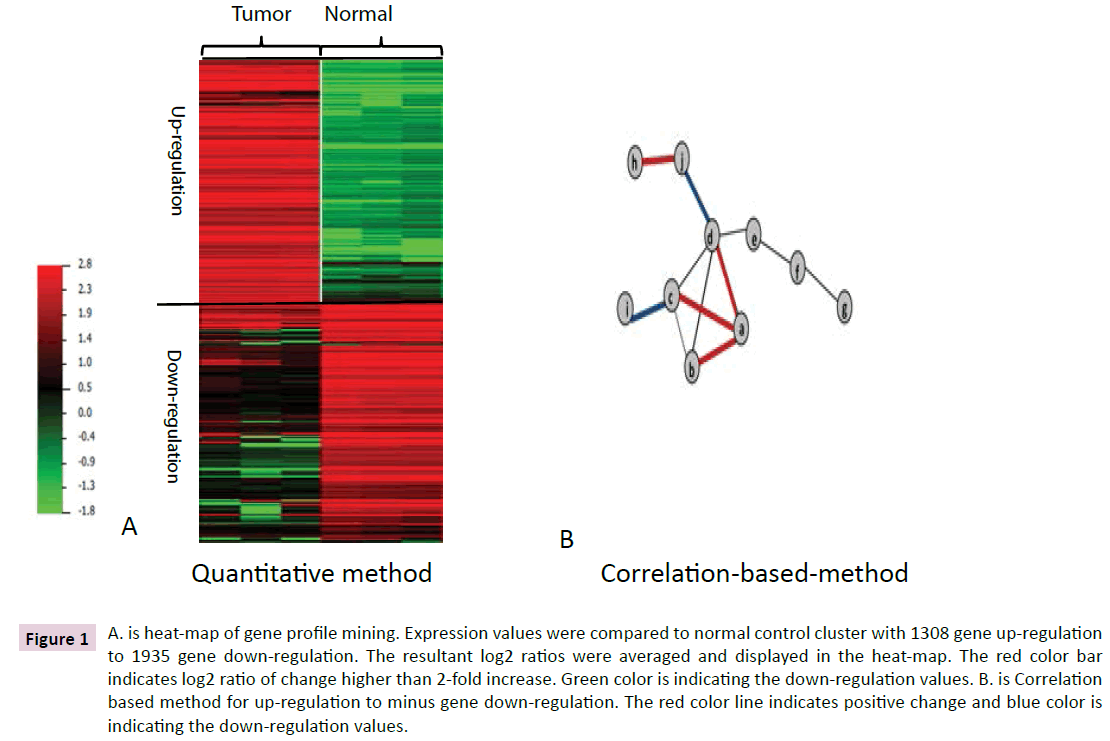
Figure 1 A. is heat-map of gene profile mining. Expression values were compared to normal control cluster with 1308 gene up-regulation to 1935 gene down-regulation. The resultant log2 ratios were averaged and displayed in the heat-map. The red color bar indicates log2 ratio of change higher than 2-fold increase. Green color is indicating the down-regulation values. B. is Correlation based method for up-regulation to minus gene down-regulation. The red color line indicates positive change and blue color is indicating the down-regulation values.
Results of therapeutic targeting identification
After harvesting genomic profile from up-regulating, we mined GES genes on therapeutic targeting identification (TI), or some genes have higher linking with most or all of tumor cell function identified by Python scripts as our previous report. DC, BC and CC (Clustering coefficient) of 1308 genes were reported as in Supplemental Table 3. Here high BC and lower DC were used as mining GES or therapeutic identification (TI). As in Table 1, 19 of 1308 genes were identified as GES by Python software based on the quantitative network analysis for targeting patient’ metastatic tumor. Because results demonstrated that 37.5% specificity with R value 0.583, an additional 19 GES genes were further mined from CBM profile about the cardiac sarcoma cells as Table 2 and Figure 1B.
| Gene |
Fold
change |
SC-1 |
SC-2 |
SC-3 |
N-1 |
N-2 |
N-3 |
scoring |
BC |
DC |
CC |
| NMUR2 |
2.13 |
6.89 |
6.45 |
6.79 |
5.87 |
5.56 |
5.42 |
1.00 |
100.00 |
1.00 |
0.00 |
| GNAI3 |
2.14 |
10.83 |
10.66 |
11.05 |
9.81 |
9.88 |
9.56 |
1.00 |
0.33 |
64.12 |
0.03 |
| KPNA2 |
4.08 |
13.51 |
13.03 |
13.38 |
11.12 |
11.28 |
11.45 |
1.25 |
0.19 |
69.33 |
0.06 |
| RACGAP1 |
3.65 |
9.98 |
10.30 |
9.81 |
7.93 |
8.00 |
8.52 |
1.00 |
0.18 |
91.88 |
0.37 |
| PTPN12 |
2.05 |
10.81 |
10.54 |
10.69 |
9.83 |
9.68 |
9.42 |
1.00 |
0.18 |
42.79 |
0.09 |
| EZH2 |
4.08 |
10.13 |
10.41 |
10.31 |
8.37 |
7.97 |
8.39 |
1.25 |
0.17 |
27.35 |
0.04 |
| TSC22D1 |
2.12 |
8.02 |
7.78 |
7.75 |
6.66 |
6.58 |
7.02 |
1.00 |
0.16 |
56.32 |
0.04 |
| PCM1 |
3.33 |
13.29 |
13.43 |
13.28 |
11.63 |
11.72 |
11.43 |
1.00 |
0.15 |
126.39 |
0.08 |
| MTMR9 |
4.84 |
11.20 |
11.58 |
11.30 |
9.18 |
8.68 |
9.35 |
1.25 |
0.14 |
13.83 |
0.00 |
| NDC80 |
2.87 |
8.85 |
8.70 |
9.33 |
7.05 |
7.83 |
7.41 |
1.00 |
0.14 |
113.88 |
0.15 |
| ZHX1 |
2.72 |
8.73 |
8.49 |
8.37 |
7.24 |
7.19 |
6.82 |
1.00 |
0.13 |
33.85 |
0.05 |
| MAD2L1 |
4.19 |
8.94 |
8.70 |
9.12 |
6.92 |
6.92 |
6.75 |
1.25 |
0.13 |
91.48 |
0.33 |
| TK1 |
3.52 |
9.40 |
9.46 |
9.22 |
7.21 |
7.77 |
7.60 |
1.00 |
0.12 |
81.30 |
0.05 |
| MSX1 |
2.52 |
9.63 |
9.28 |
9.24 |
7.79 |
7.96 |
8.37 |
1.00 |
0.12 |
107.06 |
0.14 |
| KIF5B |
2.09 |
11.89 |
11.80 |
11.56 |
10.56 |
10.65 |
10.85 |
1.00 |
0.11 |
84.68 |
0.08 |
| FANCG |
2.33 |
9.76 |
9.46 |
9.50 |
8.19 |
8.45 |
8.43 |
1.00 |
0.11 |
48.00 |
0.09 |
| CDH5 |
2.66 |
13.13 |
13.21 |
13.22 |
11.66 |
11.95 |
11.70 |
1.00 |
0.11 |
46.37 |
0.15 |
| CHEK1 |
4.21 |
9.95 |
9.55 |
10.07 |
7.38 |
7.91 |
8.03 |
1.25 |
0.11 |
82.66 |
0.26 |
| CNOT7 |
6.15 |
10.70 |
10.85 |
10.79 |
7.97 |
7.94 |
8.50 |
1.50 |
0.10 |
41.20 |
0.02 |
SC means sarcoma cells and N is normal cardiac cells. BC means “Betweenness Centrality”, DC indicates “Degree Centrality” and CC is “Clustering coefficient”.
Table 2: Results of correlation-based method.
| Genes |
BC
(100%) |
Gene Features |
Drug Discovery |
FDA approved |
| VIM |
0.34 |
sarcoma marker |
Fostriecin |
Clinical trial |
| UCP2 |
0.28 |
sarcoma/cancer marker |
N/A |
N/A |
| GRB1 |
0.23 |
cancer marker |
Quercetin |
non-FDA but common drug |
| BRCA1 |
0.23 |
cancer marker |
Tamoxifen, Mitomycin, Cisplatin, Docetaxel, Paclitaxel |
FDA |
| ESR1 |
0.22 |
cancer marker |
Fulvestrant |
FDA |
| MAP3K3 |
0.17 |
cancer marker |
N/A |
N/A |
| KPNB1 |
0.14 |
cancer marker |
N/A |
N/A |
| CPSF4 |
0.14 |
cancer marker |
N/A |
N/A |
| HSP |
0.14 |
cancer marker |
N/A |
N/A |
| CCDC85B |
0.14 |
non-tumor biomarker |
Piracetam |
FDA |
| UBE2I |
0.13 |
cancer marker |
Cisplatin/irinotecan |
FDA |
| FXR2 |
0.13 |
non-tumor biomarker |
N/A |
N/A |
| ATXN1 |
0.12 |
cancer marker |
N/A |
N/A |
| EWSR1 |
0.12 |
cancer marker |
N/A |
N/A |
| HGS |
0.12 |
cancer marker |
N/A |
N/A |
| RPS27A |
0.12 |
cancer marker |
bortezomib |
molecular therapy |
| CALM1 |
0.11 |
non-cancer marker |
Phenothiazines |
FDA |
| HSPA8 |
0.10 |
cancer marker |
geldanamycin |
FDA |
| TBP |
0.10 |
non-cancer marker |
pluramycin |
FDA |
BC means “Betweenness Centrality”
Table 3: Drug discovery from QM.
Drug discovery
After GES genes were uncovered from QM profiles and CBM profiles regarding cardiac sarcoma cells, both GES genes were input into GeneGo software and Drug-bank database, several sensitive drugs were discovered to sarcoma cells as Table 3 (QM sensitive drugs). As shown in Table 3, tamoxifen, cisplatin, docetaxel and paclitaxel are sensitive to targeting BRAC1 and bortezomib to repress RPS27A. Cisplatin and irinotecan inhibit UBE21, respectively. In order to further mining the therapeutic targeting identification (TI) related with drug discovery because of genomic profile with low specificity test, sensitivity drugs from CBM database are illuminated as shown in Table 4. Nocodazole, cisplatin and paclitaxel are sensitive to targeting MAD2L1 and mitomycin and cisplatin repress FANCG. Lenalidomide inhibit CDH5, which is vascular biomarker.
| Genes |
Gene Features |
Drug |
FDA approved |
| NMUR2 |
Non-tumor related marker |
N/A |
N/A |
| GNAI3 |
tumor related marker |
Mastoparan X |
Non-FDA approved |
| KPNA2 |
tumor related marker |
N/A |
N/A |
| RACGAP1 |
tumor related marker |
N/A |
N/A |
| PTPN12 |
tumor related marker |
N/A |
N/A |
| EZH2 |
tumor related marker |
N/A |
N/A |
| TSC22D1 |
tumor related marker |
vesnarinone |
FDA approved |
| PCM1 |
tumor related marker |
N/A |
N/A |
| MTMR9 |
tumor related marker |
N/A |
N/A |
| NDC80 |
tumor related marker |
N/A |
N/A |
| ZHX1 |
tumor related marker |
N/A |
N/A |
| MAD2L1 |
tumor related marker |
nocodazole/monastrol/paclitaxel/cisplatin |
FDA approved |
| TK1 |
Non-tumor related marker |
5-Thymidylic acid |
FDA approved |
| MSX1 |
Non-tumor related marker |
retinoic acid |
FDA approved |
| KIF5B |
tumor related marker |
N/A |
N/A |
| FANCG |
tumor related marker |
mitomycin c/cisplatin |
FDA approved |
| CDH5 |
Vascular biomarker |
Lenalidomide |
FDA approved |
| CHEK1 |
tumor related marker |
Karenitecin |
New drug |
| CNOT7 |
Non-tumor related marker |
N/A |
N/A |
Table 4: Drug discovery from CBM.
Drugs verification and clinical results
According to mining therapeutic targeting and drugs discovering, finally the both groups of GES genes were confirmed by Q-rtPCR. Drugs related with therapeutic identification genes were identified by computational analysis by Python scripts for specifically targeting the cardiac sarcoma cells as Figure 2.
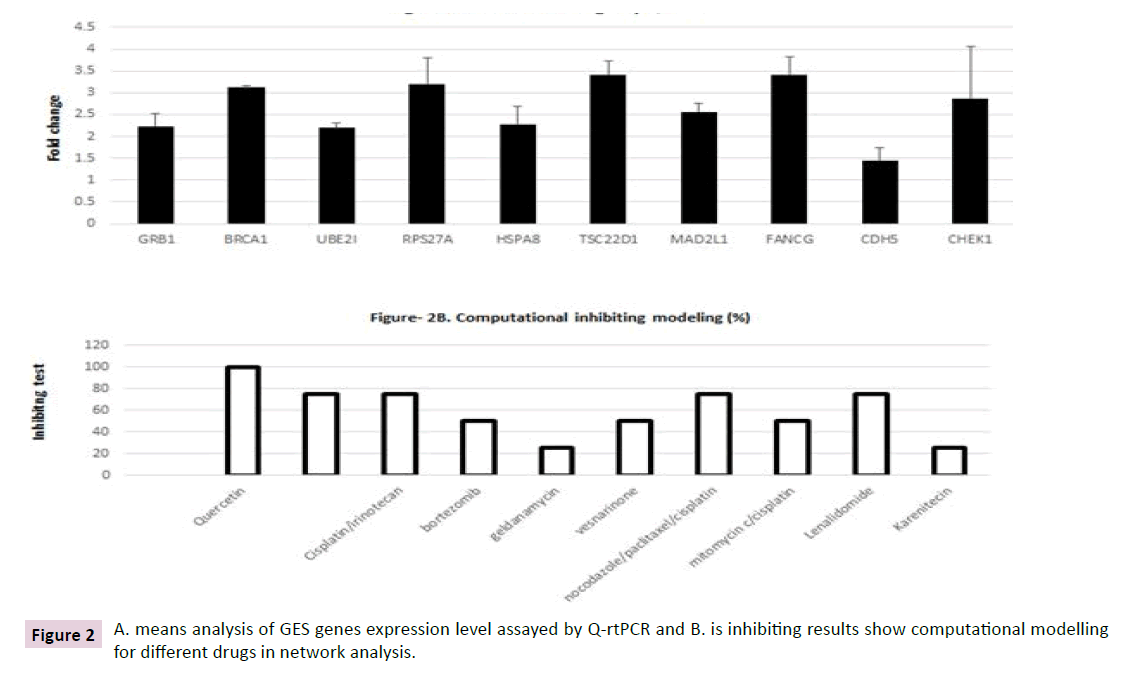
Figure 2 A. means analysis of GES genes expression level assayed by Q-rtPCR and B. is inhibiting results show computational modelling for different drugs in network analysis.
Total 10 GES genes were discovered to target drugs which have been approved by FDA. GRB1, BRCA1, UBE21, RPS27A and HSPA8 were mined by QM with targeting drugs and TSC22D1, MAD2L1, FANCG, CDH5 and CHEK1 were uncovered by CBM with target drugs as Table 5. All the targeting genes and drugs were confirmed by Q-rtPCR as Figure 2A and computational analysis shown as Figure 2B.
| |
Drugs |
FDA approval |
Dosage |
Courses |
Application methods |
Results |
| Drugs |
Paclitaxel |
Approved |
250mg |
5 |
Intravenous |
Partial response |
| Carboplatin |
Approved |
650mg |
5 |
Intravenous |
| Side-effects |
Courses |
Course-1 |
Course-2 |
Course-3 |
Course-4 |
Course-5 |
| Arrhythmia |
Yes |
Yes |
Yes |
Yes |
Yes |
| Leukopenia |
Yes |
Yes |
No |
No |
No |
| Thrombocytopenia |
Yes |
Yes |
No |
No |
No |
| Liver pain |
Yes |
Yes |
Yes |
Yes |
Yes |
| Liver Function |
Yes |
yes |
yes |
yes |
yes |
| Nausea and vomiting |
yes |
yes |
yes |
yes |
yes |
| weight gain |
No |
No |
yes |
yes |
yes |
| Edema |
No |
No |
yes |
yes |
Yes |
Table 5: Drug administration and side-effects.
Paclitaxel and carboplatin (new generation of cisplatin) were administered to the patient because combination therapy should show better response than treatment alone. After five courses of Paclitaxel and carboplatin were administered the patient, as in Figure 3, metastasis in right cardiac sarcoma, thoracic vertebra and lumber vertebra and left upper humerus have partial responses after the 2 months’ personalized therapy with observation in the following 3 months. The patient side-effects were demonstrated as Table 5.
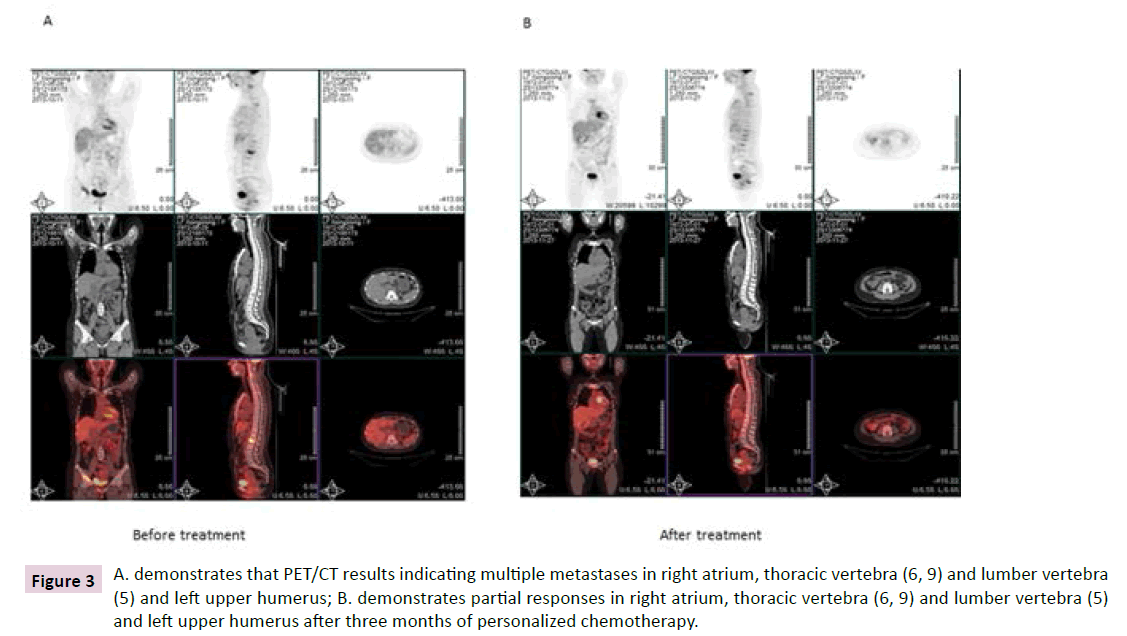
Figure 3 A. demonstrates that PET/CT results indicating multiple metastases in right atrium, thoracic vertebra (6, 9) and lumber vertebra (5) and left upper humerus; B. demonstrates partial responses in right atrium, thoracic vertebra (6, 9) and lumber vertebra (5) and left upper humerus after three months of personalized chemotherapy.
Discussion
Routinely, clinical diagnosis and management focuses on the patient medical history, and data from laboratory and imaging evaluation to diagnose and treat illnesses. After 2003, new techniques developments have provided us a more detailed understanding of the disease in individual person, such as, single nucleotide polymorphisms (SNP) and genome-wide association studies (GWAS) [12,13]. Based on the new development, personalized therapy has emerged in clinical application for drugresistance tumor disease and unknown-treatment of genetic disease and some rare disease [14]. Moreover, proteomics and transcriptome from genotype change (such as SNPs) eventually have a great impact on the new medicine [15,16]. This is because while the DNA genome is the information archive, it is the transcripts and proteins that do the work of the cell; the functional aspects of the cell are controlled by and through proteins, not gene’s DNA level [17,18]. Furthermost, most of the FDA approved drugs are directed at proteins, not DNA archives. Pharmaceutical interventions aim to modulate the aberrant protein activity, not genetic defect. Because analyses of proteins have largely found little concordance between the SNPs archives and proteomics expression, clinical scientists now make an indirect analysis of the transcriptome to search a concordance between gene expression and DNA archives due to stable and feasible data from transcriptome results [19,20].
Metastatic cardiac tumors have not uniform approach to treating these diseases and other benefits of adjuvant therapy are unclear. Here we reported the case of cardiac sarcoma treated in hospital without any efficacy about radiation therapy. Thus it is good candidate for us to administer personalized chemotherapy relying on therapeutic targeting and sensitive drug discovery. For this case, we achieve cardiac sarcoma cells and normal cardiac cells from LCM. After microarray data was normalized by MAS5, significant analysis of microarray (SAM) and Hierarchical cluster were used for mining gene expression profile. 1308 genes were higher expression by two-fold increase to compare to normal liver specimens. In order to confirm the profiles, 15 genes each were used to study sensitivity and specificity for the genomic data. Because specificity test is only 37.5% with R value 0.583, we add a Correlation Based Method to mine the profile because CBM can exclude targeting genes to normal cells by using up-regulation genes to minus down-regulation genes. After we harvest genomic profile from QM and CBM, we continue working on therapeutic targeting identification by quantitative network analysis or topology by DC and BC analysis [21]. “BC” is shortest pathway passing the protein and “DC” is how many proteins linking the proteins [22-24]. According to topology definition, or therapeutic targeting identification (TI), eventually, 19 genes selected from QM group (with higher betweenness from metastatic tissues) were identified as TI by quantitative network analysis to treat the metastasis tumor. Additional 19 GES genes were harvested from CBM. After both GES genes are input into GeneGo software and Drug-bank, two lists of drugs were discovered to treat metastasis of cardiac sarcoma. According to the drug list approved by FDA for clinical application for the tumor disease, finally medical doctors selected combination of paclitaxel and carboplatin for the patient’s treatment plan. After five courses of personalized chemotherapy by combination of paclitaxel and carboplatin, we successfully achieve a partial response for multiple metastases in right atrium, thoracic vertebra, lumber vertebra and left upper humerus.
Author’s Contributions
BL conceived, designed and guided the work and edited the manuscript. HSX, JSH and XNZ performed experiments including RNA specimen preparation and BL processed bioinformatics process and drugs validation. YG and BL supported clinical work.
Acknowledgement
The inclusion of trade names or commercial products in this article was solely for the purpose of providing specific information and does not imply recommendation for their products.
References
- Schilsky RL (2010) Opinion: Personalized medicine in oncology: the future is now. Nature Reviews Drug Discovery 9:363-366.
- Hudson TJ (2013) Genome variation and personalized cancer medicine. J Intern Med 274:440-450.
- Li B, Senzer N, Rao DD (2008). Bioinformatics Approach to Individual Cancer Target Identification, 11th Annual Meeting of the American Society of Gene Therapy, C8, 451004.
- Li B (2012) Clinical Genomic Analysis and Diagnosis --Genomic Analysis Ex Vivo, in Vitro and in Silico. Clinical Medicine and Diagnostics 2:37-44.
- Modesitt SC, Hsu JY, Chowbina SR, Lawrence RT, Hoehn KL (2012) Not all fat is equal: differential gene expression and potential therapeutic targets in subcutaneous adipose, visceral adipose, and endometrium of obese women with and without endometrial cancer. Int J Gynecol Cancer 22:732-741.
- Coda AB, Icen M, Smith JR, Sinha AA (2012) Global transcriptional analysis of psoriatic skin and blood confirms known disease-associated pathways and highlights novel genomic "hot spots" for differentially expressed genes. Genomics100:18-26.
- Spetsieris PG, Ma Y, Dhawan V, Eidelberg D (2009) Differential diagnosis of parkinsonian syndromes using PCA-based functional imaging features. Neuroimage 45:1241-1252.
- Zhao Y, Simon R (2008) BRB-ArrayTools Data Archive for human cancer gene expression: a unique and efficient data sharing resource. Cancer Inform 6:9-15.
- Narayanan T, Gersten M, Subramaniam S, Grama A (2011) Modularity detection in protein-protein interaction networks. BMC Res Notes 4:569.
- Lin D, Cao H, Calhoun VD, Wang YP (2014) Sparse models for correlative and integrative analysis of imaging and genetic data. J Neurosci Methods 237:69-78.
- Zheng J, Zhang D, Przytycki PF, Zielinski R, Capala J, Przytycka TM (2010) SimBoolNet--a Cytoscape plugin for dynamic simulation of signaling networks. Bioinformatics 26:141-142.
- Manolio TA, Guttmacher, Alan E, Manolio, Teri A (2010) Genomewide association studies and assessment of the risk of disease. N. Engl. J. Med 363: 166–176.
- Pearson TA, Manolio TA (2008) How to interpret a genome-wide association study. JAMA 299: 1335–1344.
- Quayle AP, Siddiqui AS, Jones SJ (2007) Perturbation of interaction networks for application to cancer therapy. Cancer Inform5:45-65.
- Mansour JC, Schwarz RE (2008) Molecular mechanisms for individualized cancer care. J. Am. Coll. Surg 207:250–8.
- van't Veer LJ, Bernards R (2008) Enabling personalized cancer medicine through analysis of gene-expression patterns. Nature 452:564–570.
- SaglioG, Morotti A, Mattioli G (2004) Rational approaches to the design of therapeutics targeting molecular markers: the case of chronic myelogenous leukemia. Ann N Y AcadSci 1028:423–31.
- Oldenburg J, Watzka M, Rost S, Müller CR VKORC (2007) molecular target of coumarins. J. Thromb. Haemost. 5 Suppl 1:1–6.
- Anderson NL, Anderson NG (1998) Proteome and proteomics: new technologies, new concepts, and new words. Electrophoresis19:1853–61.
- Subramanian A, Tamayo P, Mootha VK, Mukherjee S, Ebert BL, Gillette MA, Paulovich A, Pomeroy SL, Golub TR, Lander ES, Mesirov JP (2005) Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. ProcNatlAcadSci USA 102:15545-50.
- Wang Z, Gerstein M, Snyder M (2009) RNA-Seq: a revolutionary tool for transcriptomics. Nature Rev. Genetics 10:57-63.
- Letwin NE, Kafkafi N, Benjamini Y, Mayo C, Frank BC, Luu T, Lee NH, Elmer GI (2006) Combined application of behavior genetics and microarray analysis to identify regional expression themes and gene-behavior associations. J Neurosci 26:5277-87.
- Zielinski R, Przytycki PF, Zheng J, Zhang D, Przytycka TM, Capala J (2009) The crosstalk between EGF, IGF, and Insulin cell signaling pathways--computational and experimental analysis. BMC SystBiol 3:88.
- Carlson SM, White FM (2011) Using small molecules and chemical genetics to interrogate signaling networks. ACS ChemBiol 6:75-85.