Keywords
Weka; Network security; Precision; Recall; IDS; KDDCUP 99; Machine
learning
Introduction
The Disruption Detection System (IDS) was viewed as the "silver
projectile" that ensures the security of an association office against
potential assaults. Albeit after the extension of this methodology,
it isn't utilized adequately because of the enormous measure
of bogus admonitions it does. For instance, the notable open
source interruption discovery framework Snort Strategy runs in
an association with two or three hundred machines and makes
countless cautions each day, containing a large portion of the
bogus alarms. More often than not, the IDS movement creates
a colossal measure of results that ordinarily show up at the
affiliation's Security Operations Center (SOC), bringing about an
amazingly idealistic exertion and long work to do [1]. To conquer
this issue, examiners generally produce careful IDS rules (hails)
that expressly limit amazingly precise adjusts and lessen the by and
large bogus positive (FP) rate. Notwithstanding, this outcomes in
the dissatisfaction of disengaging various animosities or various
sorts of hostilities zeroed in the polymorphic characters of the
animosities, which is going to be an effect of the human instinct
behind them. Besides, to stop negatives which are false (FN), for
example the disclosure is lost, the IDS system experts resort to
uniting past techniques with a more non-restrictive structure, so
a movement with even a far off plausibility of confronting the
attack would trigger an alert.
Materials and Methods
Intrusion detection systems
Computerized assaults on PCs, associations and governments
have become regular events in which the security, enduring
quality and accessibility of the PC systems being referred to are
penetrated. Subsequently, a system should be set up that can
perceive and forestall these assaults on a host or PC association.
Thusly, various planes and constructions appear to robotize this
collaboration. Different terms of IDS are the accompanying:
Intrusion: A push to arrange secrecy, honesty or expected
accessibility (CIA) in a PC office or association.
Intrusion detection: Strategy to recognize events happening in
a PC affiliation or association and investigate them for blackout
terms [2].
Intrusion Detection System (IDS): part of a conspiratorial item or
hardware that automates the strategy for identifying blackouts
(Table 1).
| Attack category |
Attacks in KDDCup99 dataset |
| DO |
apacha2,back,land,mailbomb,neptune,pod,processtable,smurf,teardrop,udpstorm |
| U2R |
buffer_overflow,httprunnel,oadmodule,perl,ps,rootkit,sqlattack,xterm |
| R2L |
ftp_write, guess password, imap, multihop, named, phf, sendmail, snmpgetattack,
snmpguess, spy, warezclient, warezmaster, worm, xlock, xsnoop |
| Probing |
ipsweep,Mscan,Namp,portsweep,saint,satan |
| Normal |
Normal |
Table 1: Attack categories of KDDcup99 dataset.
Intrusion Prevention System (IPS): Conspiring to keep up every
one of the abilities of the IDS yet could likewise successfully
forestall potential events.
Host-based IDS (HIDS): Conspires that it exists as a trained
professional or host on the local PC and cautions of the machine's
conduct, for instance, by investigating the logs (Table 2).
| Category of attack |
No of samples |
| U2R |
228 |
| Probe |
4165 |
| Total |
311014 |
| Normal |
60589 |
| DoS |
229853 |
| R2L |
16179 |
Table 2: No of samples in the Kddcup99 Test dataset.
Network-based IDS (NIDS): A diagram that cautions of organization
traffic, generally comprised of sensors dissipated all through
the association and an administration unit. Sensors recognize
network parcels, like TCP/IP bundles, and the plan attempts to
identify noxious parcels or odd action in the association [3].
Detection approaches
Mostly clean outage localization techniques after rankings
Identification based on abuse or signature: A trademark is a
model that is related to a perceived aggression or danger, the
identification of abuse is the strategy to counter the models with
detected events with the recognition of possible interruptions.
Fights comparable to most antivirus programs [4]. Check the
organization for behaviors that have been predestined as harmful.
They are amazing and fast as they are simply sifting through what
they are noticing and a predetermined pattern. Signature-based
IDS will not recognize the farthest dangers. As another assault
follows, the information records can be updated before the
organization becomes unstable. IDS Anomaly-based: Anomalybased
recognition basically depends on the characterization of
the organization's exercises. The organizational exercises are
the predefined ones, when the occasion is recognized or, in all
probability, promulgated in place of incongruity [5]. The perceived
exercises of the organization are orchestrated or instructed by the
determinations of the organization's administrators. The critical
phase in the characterization of organizational exercises is the IDS
engine capable of crossing the various conventions at all levels.
The motor can execute shows and comprehend the objective.
With this show, the test is computationally costly, the advantage
it produces, for example, extending the standard wizard set into
less bogus positive alarms. The principle obstruction to peculiarity
based disclosure is the portrayal of your arrangement of norms.
The plausibility of the arrangement depends on the execution
and testing of every available understanding (Table 3).
| Bayes Net |
Naïve Bayes |
J48 |
J48Graft |
Random Forest |
Individual attack Class |
Merit |
| 0.998 |
0.924 |
0.989 |
0.993 |
0.996 |
apache2 |
Prototype tool |
| 0.997 |
0.996 |
0.996 |
0.997 |
1 |
back |
Fast implementation of solutions |
| 0.177 |
0.028 |
0.526 |
0.727 |
0.588 |
buffer_overflow |
Prototype tool |
| 0.996 |
0.859 |
0.995 |
0.996 |
0.999 |
guess_passwd |
Fast implementation of solutions |
| 0.779 |
0.644 |
0.92 |
0.929 |
0.991 |
httptunnel |
Prototype tool |
| 0.674 |
0.326 |
0.989 |
0.989 |
0.984 |
ipsweep |
Fast implementation of solutions |
| 0.06 |
0 |
1 |
1 |
1 |
land |
Prototype tool |
| 1 |
0.959 |
0.999 |
0.998 |
1 |
mailbomb |
Fast implementation of solutions |
| 0.971 |
0.853 |
0.988 |
0.985 |
1 |
mscan |
Prototype tool |
| 0.998 |
0.998 |
1 |
1 |
1 |
neptune |
Fast implementation of solutions |
| 0.897 |
1 |
1 |
1 |
1 |
nmap |
Prototype tool |
| 0.886 |
0.777 |
0.95 |
0.95 |
0.951 |
normal |
Fast implementation of solutions |
| 0.716 |
0.132 |
0.904 |
0.917 |
0.957 |
pod |
Prototype tool |
| 0.886 |
0.843 |
0.954 |
0.959 |
0.988 |
portsweep |
Fast implementation of solutions |
| 0.998 |
0.986 |
0.998 |
0.996 |
1 |
processtable |
Prototype tool |
| 0.286 |
0.01 |
0.167 |
0.2 |
0.5 |
ps |
Fast implementation of solutions |
| 0.766 |
0.023 |
0.94 |
0.94 |
0.926 |
saint |
Prototype tool |
| 0.905 |
0.821 |
0.97 |
0.97 |
0.968 |
satan |
Fast implementation of solutions |
| 1 |
0.997 |
1 |
1 |
1 |
smurf |
Prototype tool |
| 0.582 |
0.469 |
0.636 |
0.636 |
0.634 |
snmpgetattack |
Fast implementation of solutions |
| 0.961 |
0.324 |
0.998 |
0.998 |
0.998 |
snmpguess |
Prototype tool |
| 0.89 |
0.556 |
0.989 |
0.989 |
0.992 |
warezmaster |
Fast implementation of solutions |
| 0.964 |
0.926 |
0.98 |
0.98 |
0.981 |
Weighted Avg |
Prototype tool |
Table 3: Kddcup99 dataset precession for all classifier individual attacks.
IDS Spec-based: In this system, really extended estimates are
used to explain the supported program. This methodology
depends on the ordinary explanations made by the merchant
to express actions that allow him to follow the states of the
agreement. In general, the association shows that the projects in
Determination Base IDS are based on the guidelines of the world
principles that limit the fair. The advantage of this procedure is
that it does not produce false alerts when legal acts of unknown
clients are attempted. Also, you can perceive the weak assaults
of the past in light of your ability to recognize assaults that
deviate from predetermined legitimate exercises. In any case, the
prerequisite progress for such a technique requires critical effort,
which affects the appropriateness of the approach. Furthermore,
the productivity of the decrease in false positives remains
implausible (Table 4).
| Bayes Net |
Naïve Bayes |
J48 |
J48Graft |
Random Forest |
Individual attack Class |
| 1 |
0.861 |
0.982 |
0.982 |
0.996 |
apache2 |
| 0.995 |
0.992 |
0.997 |
1 |
1 |
back |
| 0.097 |
0.014 |
0.417 |
1 |
0.5 |
buffer_overflow |
| 0.999 |
0.876 |
0.996 |
0.998 |
0.999 |
guess_passwd |
| 0.664 |
0.487 |
0.963 |
0.981 |
1 |
httptunnel |
| 0.514 |
0.196 |
1 |
1 |
0.989 |
ipsweep |
| 0.031 |
0 |
1 |
1 |
1 |
land |
| 1 |
0.943 |
0.998 |
0.996 |
1 |
mailbomb |
| 0.948 |
0.756 |
0.989 |
0.984 |
1 |
mscan |
| 1 |
1 |
1 |
1 |
1 |
neptune |
| 0.813 |
1 |
1 |
1 |
1 |
nmap |
| 0.998 |
0.999 |
0.953 |
0.953 |
0.954 |
normal |
| 0.567 |
0.071 |
0.868 |
0.892 |
0.971 |
pod |
| 0.818 |
0.79 |
0.991 |
0.991 |
1 |
portsweep |
| 1 |
0.992 |
1 |
1 |
1 |
processtable |
| 0.211 |
0.005 |
0.333 |
1 |
1 |
ps |
| 0.788 |
0.026 |
0.95 |
0.95 |
0.93 |
saint |
| 0.884 |
0.71 |
0.964 |
0.966 |
0.978 |
satan |
| 1 |
0.996 |
1 |
1 |
1 |
smurf |
| 0.411 |
0.383 |
0.618 |
0.618 |
0.618 |
snmpgetattack |
| 0.928 |
0.195 |
0.999 |
0.999 |
1 |
snmpguess |
| 0.804 |
0.748 |
0.989 |
0.998 |
0.991 |
warezmaster |
| 0.981 |
0.965 |
0.981 |
0.981 |
0.981 |
Weighted Avg |
Table 4: Kddcup99 dataset all classifier RECALL for individual attacks.
Mixed ID: Hybrid IDs are represented by both the strategy used
to distinguish assaults and IDS activity in the organization. IDS
can perform anomaly recognition or abuse tracing and can be
provided as an organization-based framework or as a host-based
technique. These consequences in four regular meetings have
specifically abuse, organizational abuse and host anomaly and
network of inconsistencies (Table 5) [6]. Some IDS consolidate
the characteristics of each of these classes (mainly by identifying
both abuse and rarity) and are perceived as mixed frames. It is
imperative to create the vital contrasts between the recognition
of anomalies and the approaches to the site of abuse [7].
| Bayes Net |
Naïve Bayes |
J48 |
J48Graft |
Random Forest |
Individual attack class |
| 1 |
0.999 |
0.998 |
0.998 |
1 |
apache2 |
| 1 |
1 |
1 |
0.997 |
1 |
back |
| 1 |
0.975 |
0.928 |
0.856 |
0.929 |
buffer_overflow |
| 1 |
0.994 |
0.997 |
0.997 |
1 |
guess_passwd |
| 0.998 |
0.997 |
0.961 |
0.942 |
0.992 |
httptunnel |
| 0.993 |
0.988 |
0.994 |
0.994 |
0.998 |
ipsweep |
| 1 |
1 |
1 |
1 |
1 |
land |
| 1 |
0.999 |
1 |
1 |
1 |
mailbomb |
| 1 |
1 |
0.997 |
0.999 |
1 |
mscan |
| 1 |
0.999 |
1 |
1 |
1 |
neptune |
| 1 |
1 |
1 |
1 |
1 |
nmap |
| 0.997 |
0.98 |
0.998 |
0.998 |
0.998 |
normal |
| 1 |
0.976 |
0.971 |
0.971 |
1 |
pod |
| 1 |
0.999 |
0.988 |
0.988 |
1 |
portsweep |
| 1 |
0.998 |
0.998 |
0.998 |
1 |
processtable |
| 0.997 |
0.992 |
0.886 |
0.83 |
0.944 |
ps |
| 0.999 |
0.969 |
0.992 |
0.988 |
0.988 |
saint |
| 1 |
0.999 |
0.996 |
0.944 |
0.994 |
satan |
| 1 |
0.997 |
1 |
1 |
1 |
smurf |
| 0.989 |
0.977 |
0.99 |
0.99 |
0.99 |
snmpgetattack |
| 1 |
0.993 |
0.999 |
0.999 |
1 |
snmpguess |
| 1 |
0.997 |
0.997 |
0.998 |
1 |
warezmaster |
| 0.999 |
0.994 |
0.999 |
0.999 |
0.999 |
Weighted Avg |
Table 5: Kddcup99 dataset F. All classifier measure for individual attacks.
The fundamental issues IDS finds are countless bogus positive
alarms that are erroneously designated to common traffic
because of safety penetrates. An ideal IDS doesn't give bogus
or irrelevant alarms. Practically speaking, signature-based IDSs
amass to make extra bogus cautions than anticipated. This is
because of the preposterous number of votes and the shortfall
of a fundamental confirmation apparatus to affirm the finish
of the round. The goliath number of empowering bogus spots
in the caution log makes the system of taking a helpful action
for genuine positives, like successful adjusts postponed and
escalated endeavors (Table 6).
| Bayes Net |
Naïve Bayes |
J48 |
J48Graft |
Random Forest |
Individual attack class |
| 0.996 |
0.996 |
0.996 |
0.996 |
0.996 |
apache2 |
| 1 |
1 |
0.995 |
0.995 |
1 |
back |
| 1 |
0.714 |
0.714 |
0.571 |
0.714 |
buffer_overflow |
| 0.993 |
0.844 |
0.994 |
0.994 |
1 |
guess_passwd |
| 0.983 |
0.949 |
0.881 |
0.881 |
0.983 |
httptunnel |
| 0.979 |
0.968 |
0.979 |
0.979 |
0.979 |
ipsweep |
| 1 |
0 |
1 |
1 |
1 |
land |
| 1 |
0.976 |
1 |
1 |
1 |
mailbomb |
| 0.995 |
0.978 |
0.986 |
0.986 |
1 |
mscan |
| 0.996 |
0.995 |
1 |
1 |
1 |
neptune |
| 1 |
1 |
1 |
1 |
1 |
nmap |
| 0.797 |
0.636 |
0.947 |
0.947 |
0.948 |
normal |
| 0.971 |
0.914 |
0.943 |
0.943 |
0.943 |
pod |
| 0.968 |
0.904 |
0.92 |
0.928 |
0.976 |
portsweep |
| 0.996 |
0.98 |
0.996 |
0.992 |
1 |
processtable |
| 0.444 |
0.778 |
0.111 |
0.111 |
0.333 |
ps |
| 0.746 |
0.02 |
0.93 |
0.93 |
0.922 |
saint |
| 0.927 |
0.973 |
0.976 |
0.974 |
0.958 |
satan |
| 1 |
0.999 |
1 |
1 |
1 |
smurf |
| 0.992 |
0.606 |
0.654 |
0.654 |
0.65 |
snmpgetattack |
| 0.996 |
0.971 |
0.996 |
0.996 |
0.996 |
snmpguess |
| 0.998 |
0.442 |
0.988 |
0.989 |
0.993 |
warezmaster |
| 0.958 |
0.909 |
0.98 |
0.98 |
0.98 |
Weighted Avg |
Table 6: Kddcup99 dataset all classifier ROC for individual attacks.
Literative survey
In recent times, many inexpensive and non-commercial intrusion
detection looms have been developed that characterize loom
breaks. The latest techniques are used to improve the pace
of development of this type of plan. Information extraction
procedures could cope with colossal data sets and enable the
mechanization of IDS. The close inconsistency recognition models
have been expanded to recognize a break with a tremendous
level of precision. As the evaluated research indicates, two
types of profiling are performed. A few IDS structures support
a conceivable data base about the plan of an interfere with
movement and trigger alert when that action is perceived. These
edges create less bogus cautions considering a qualification in
center use designs; in any case, troublesome conduct is probably
going to be disparaged with the new models. Another class of IDS
plans keeps a normal operational profile displayed by a learning
association. Anything outside of this social profile is delegated a
possible disturbance. These plans have a prevalent bogus caution
rate, anyway they are bound to choose in case of a blackout. Xiao
and his colleagues introduced an outage location strategy that GA applies to distinguish outages in networks during important
component selection techniques. His method uses data
hypothesis to extract related highlights and reduce problems.
From that point on, they established a simple construction rule
from the chosen highlights to classify the network exercises into
typical and irregular exercises. Be that as it may, your strategy
only thinks about the highlights that go unnoticed [8]. Ciaulkns et
al. have expressed a powerful information excavation framework
to distinguish anomalies using the tree of choice in networks
[9]. Gudadhe et al. introduced a model that uses the compatible
choice tree, such as the hoeffding tree order strategy to improve
competence in the recognition of interruptions.system [10].
The upgrade procedure improves crew execution by using a
versatile window and reaching the flight tree as the basic student.
The essential thinking of the impulse is to combine simple
standards to frame an outfit with the ultimate goal of enhancing
the effectiveness of the unique collectible component. The
momentum calculation begins by providing all the information
by preparing the tuples of the comparable weight w0. After
assembling a classifier, the heap of each tuple changes according
to the order given by that classifier. At that time, a subsequent classifier is developing the reloaded prepare tuple. The order
of arrival of the break position is a normal stacking of individual
large sorter orders.
Skillet et al. expressed a conspiracy about the location of
abuse using the neural organization collection and the C4.5
calculation [11]. Gaddam et al. expressed the conspiracy for the
direct identification of peculiarities through the clustering of
descendant K-Means and ID3 decision tree learning calculations
[12]. Yasami and Mozaffari expressed host-based IDS using a
collection of K-Means clusters and ID3 decision tree learning
calculations used to classify unusual and ordinary behaviors in
existing organizations [13].
In almost all inspection work, SVM was used to organize the
organization's traffic projects. The problem with this strategy is
that it takes time to prepare the plan. Therefore, it is important to
simplify the problem by using groupings, fluid rational inheritance
calculations, and neural organizations. Platt expressed a rapid
preparation method for SVM using negligible subsequent
advances [14].
Khan et al. [15] introduced a strategy to streamline the SVM
preparation season, especially when dealing with large data sets,
using a progressive clustering survey. From them, a powerful
automatic growth has been used that obtains the calculation of
the trees to be grouped, since it has been shown that it solves the
problems of the different existing grouping calculations by levels.
The clustering test helps to find marginal approaches, which are
mainly information models equipped to prepare SVM, between
two classes, rare and ordinary. Its calculation has contributed
enormously to improve the SVM preparation phase with the
prevailing speculative precision. Guo et al. [16] proposed an epic
calculation for multiclass SVM. The working tree in the calculus
includes a two-class SVM sequence.
Mulay et al. [17] selected SVM-dependent IDS using the tree
of choice. Chen and her colleagues applied the support vector
machine to multiclass classification problems and solved
multiclass debugging errors. They estimated the limits of the
ordinary strategies and from now on they designed the SVM
based on the Decision Tree (DTSVM) that uses the hereditary
calculation (GA) that saves the maximum capacity for speculation.
Yi et al. [18] projected an altered radial base part function (U-RBF),
through the positive sides of the mean and the root of the mean
square of the highlighted credits embedded in the radial base bit
function (RBF). They suggested an updated work of the U-RBF
stepper bit, which depends on the work of the Gaussian part.
This technique reduces the hustle and bustle among subscribers,
thus the recognition rate of U-RBF is higher than that of RBF. The
U-RBF plays a vital role in saving time in preparation and testing.
This strategy is useless for finding root (U2R) and far-to-near
(R2L) client attacks [19].
Machine learning algorithms
We have checked our proposed methodology in different manmade
consciousness computations and determined the outcomes
of the request; we assemble these equivalent computerized reasoning estimations. The AI computations appeared beneath
will frame the reason for the sweeps performed with our
proposed strategy.
BayesNet: BayesNet learns dubious Bayesian associations as
clear characteristics with no missing characteristics. These
two are absolutely novel parts for assessing the association's
prohibitive likelihood tables. In our investigation, we will
commonly run BayesNet with the Simple Estimator and the K2
query computation without utilizing AD Tree. The estimation of
K2 is done as follows. We are holding back to perceive the full
interest for center points. First and foremost, each middle doesn't
have individuals. At that point the computation progressively
allocates the network whose development will improve the vast
majority of the score of the subsequent design. At the point when
no extension of a parent improves the score, he quits partner
the gatekeepers in the middle. As interest from the focuses has
been noticed up until now, the observing space underneath this
necessity is significantly more unassuming than the complete
region. Likewise, you don't should be compelled to check for
circles, as the absolute interest guarantees that there are no
circles inside the discovered activities (Figure 1) [20].
NaiveBayes classifier: Along with choice trees, neural affiliations,
closest neighbors, the most sensible learning approach is
presumably the NaiveBayes classifier. The NaiveBayes classifier
is used when a moderate or enormous course of action of
preparation is possible or when the properties that clarify the
occasions are momentarily self-administering given the depiction
construes the objective work. f∶X → V, where each occasion x
clarified by the attributes {a1, a2,… a}. vNB=arg max P (vj) �� P
(man-made intelligence |vj)vj��V
J48 decision trees: The J48 Decision Tree is an insightful manmade
mental ability model that picks the target worth from another model ward on a couple of positive pieces of the idea
of information reachable. The inner focal points of a choice tree
address explicit credits, while the branches between the spotlights
give data on the potential attributes that these properties can
achieve in the exhibited models, while the terminal living spaces
educate on the last worth (disposition) of the dependent variable.
In the J48 framework, to demand something different, you ought
to at first settle on a decision tree that relies upon the quality
benefits of pragmatic course of action information. Along these
lines, when you experience a ton of things (the course of action
set), you see the property that disconnects the different models
even more doubtlessly. This part that can isolate information
even more exactly is said to get the most surprising data. As
of now, among the normal advantages of this part, if there is a
persuading power for which there is no weakness, that is, for
which the information openings are of their sort, they have the
same stimulus for the objective variable, by then we end that
branch and property to it the objective regard that we have
acquired [21].
J48graft: J48graft produces a decision tree joined by a J48 tree.
The combination framework associates the concentrations
to a current decisions tree with an assurance to diminishing
suspicion botches. These assessments see spaces in the model
space that don't have all of the characteristics to be incorporated
through event masterminding, or included solely by misclassified
coordinating cases, and think about the various courses of
action for those spaces. In elective words, replacement tests are
done inside the leaf, making new branches that can deliver new
demands. Join is an algorithmic norm for stretching out focus
focuses to the tree as a post processor. Their explanation is to
grow the opportunity of reliably mentioning openings that dive
outside of the spaces covered by the status data. Join can be
a post processor that will be applied to the choice trees. Your
duty is to diminish the supposition botch by renaming space
event regions where there is no status data or where there is
simply misclassified information. Its inspiration is to find the best
arranged with existing leaf region cuts and branches bound to
make new leaves with elective perspectives concerning those
under. But that tree is changed into a ton of forefront; in any
case, here it is seen as exclusively a fragment that doesn't present
slip-ups of solicitation in the information recently mentioned in
a sensible way. The new tree committed as requirements be
reduces errors rather than presenting them [22,23].
Proposed work
The appended computation 1 was utilized as the proposed
estimation. The KDD cup99 dataset contains a huge load of
individual assaults like apache2, back, xterm, and so on, from
the start the dataset is taken care of to take out inconsistencies.
When the inconsistencies have been wiped out by then, the
individual rounds are supplanted by their positioning as shown
in Algorithm I.
Calculation 1
Data: KDD cup 99 Dataset
Execution: WEKA .ARFF practicable record in which all assaults are gathered freely
Stage 1: release abnormalities from the dataset
Stage 2: assuming attack_read == 'apache2' by/find all 'apache2'
attacks supersede the assault of Cat1 in the KDD dataset
Stage 3: regardless if attack_read == 'back then's/look for each
'attack from behind'
spoof the Cat2 round in the KDD dataset/change this development
for all individual rounds in the KDD cup99 dataset
Step n: regardless in the event that attack_read == 'xterm' by/find
all assaults 'xterm' replaces the Catn assault in the KDD dataset
Step n+1: Otherwise, mark as commonplace in the KDD cup
dataset
Step n+2: accumulate the file and save it as individual_attacks.
arff
In the wake of getting individual_attacks.arff, we run it on
the WEKA mechanical gathering to assert the capacity of the
depiction of our proposed strategy. Thus, we have used the Bayes
Net, Naïve Bayes, J48, J48graft, Random Forests classifiers.
Results and Discussion
Our technique was considered utilizing the aggravation
informational index from the KDD Cup99 network. It shows
up from the DARPA 98 Intrusion Detection Assessment met by
MIT's Lincoln Research Facility. This is viewed as a standard data
understanding approach that ties the test plan and sets together.
c. What's more, the test suite joins fourteen days of uniform and
separated traffic with roughly 3 million members. In this archive,
we utilize the KDD information list interface. Table 2 shows the
degree of the demand. By then, the assessment extricates 10%
of the information. 66% of this new establishment was decreased
with the arrangement set and 34% went to the test set. Likewise,
in the KDD Cup dataset, there are 37 open assault types in the
test set, however just 23 of them are in the fix set. In this way, the
test bundle can be utilized to check the region's pace of new or
powerless assaults.
Exactness and detection rate of proposed method: The
assessments used for surveying the presentation of proposed
method are exactness (i.e., Precision) and assertion rate (i.e.,
Recall). Exactness is the level of the firm number of assaults
that are appropriately seen. It is compelled by the going with
condition.

Affirmation Rate is depicted as the measure of assaults perceived
by the proposed procedure to beyond question the amount of
assaults truly there.
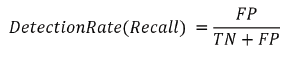
Here, TP is True Positive, FP is False Positive, and FN is False Negative. A TP is a case, which is really an assault and is seen as
assault by the proposed system. A FP happens when proposed
system sees a standard development as assault activity. A FN
emerges when the proposed strategy sees an assault activity
as typical. An action that joins accuracy and overview is the
symphonious mean of exactness and review is viewed as F
measure.
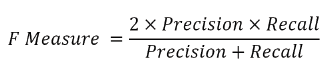
Characteristics of the getting manager (ROC): ROC tends to the
exchange among affectivity and attitude. The ROC twists plot the
PT rate versus the FP rate, in separating limit shorts.
The consequences of exploratory exactness with the various
classifiers utilized are appeared in Table 3. As should be
obvious, the Naïve Bayes Classifier show is more startling than
typical. Essentially, Tables 4-6 show the presentation of Recall, F
measures, Bayes Net ROC, Naïve Bayes, J48, J48 join and Random
Forrest for the acknowledgment of individual assaults. Hence,
three classifiers J48, J48 Graft, and Random Forrest effectively see
the unmistakable assault bunches from the KDDCup'99 dataset.
Subsequently, these two appraisals can be appropriately shipped
off any AI-based IDS to see the assault modes appeared in Table
1.
Conclusion
From now on, these myriad strategies, strategies and gadgets
are used to distinguish the intrusion in the PC organization and
we proceed with the investigation to make them far superior to
the perception of the interruption. In any case, in the meantime,
new assaults have emerged that will be difficult for Handel as he
progresses with changes in his practices. In this scouting work, we
have proposed "an improved strategy to identify disruption using
AI calculations" with the KDDCUP 99 data set, which is recreated
on the WEKA instrument. The proposed technique distinguishes
the unique attacks present in the KDDCUP 99 dataset quickly and
efficiently. The identification rate for each of the three IA J48,
J48 Graft, and Random Forrest calculations is greater than 96%.
These calculations can be adjusted for the organization's climate
to improve recognition speed and time. In the future, we may
change the default WEKA limits with a decrease in the highlights
of the KDDCUP 99 dataset. In addition to the combination
of machine learning calculations and information extraction
techniques, we can use computerized reasoning and delicate
computational strategies. Such as neural organizations and and
so on, which could reduce the false caution rate when identifying
outages.
References
- Zhou Z, Chen Z, Zhou T, Guan X (2010) The study on network intrusion detection system of Snort. IEEE 2: 194-196.
- Liao, Hung J, Chun H, Richard L, Ying CL, Kuang YT, et al. (2013) Intrusion detection system: A comprehensive review. J Netw Comput Appl 1: 16-24.
- Debar, Herve (2000) An Introduction to Intrusion-Detection Systems. Proceedings of Connect 4: 1-18.
- Jyothsna V, Rama Prasad VV, Prasad KM (2008) A review of anomaly based intrusion. Int J Comput Appl 28:26-35.
- Bashah, Norbik, Idris BS, Abdul MA (2005) Hybrid intelligent intrusion detection system. WASET 11: 23-26.
- Ghosh, Anup K, Aaron S, Michael S (1999) Learning Program Behavior Profiles.IEEE 4:3-7.
- Xia, T, Guangzhi Q, Salim H, Mazin Y, (2005) An efficient network intrusion detection method based on information theory and genetic algorithm. IEEE 8: 11-17.
- Sai NR, Krishna NV, Reddy MC, Sumiran MS (2020) An efficient high energy based routing protocol for wireless sensornetworks. Test Eng Manag 29:1-7.
- Sai DNR (2020) Analysis of artificial neural networks based intrusion detection system. Int J Adv Sci Technol 29: 11-19.
- Zhang CT, Zhang Z, He Z (1998) Prediction of the secondary structure content of globular protein based on three structural classes. J Protein Chem 17: 261-272.
- Raghavendra SN (2020) A Multi Resolution Convolution Neural NetworK Based Face Recognition Analysis. J Crit Rev 7:12-18.
- Jogendra KM, Raghavendra SN, Smitha C (2020) An efficient deeplearning approach for brain tumor segmentation using cnn iop conference series. Mater Sci Eng C 981: 1121-1125.
- Sai NR, Jogendra KM, Smitha C (2020) A secured and effective load monitoring and scheduling migration vm in cloud computing iop conference series. Mater Sci Eng C 981:1126-1129.
- Kumar MJ, Kumar GV, Krishna PS, Sai NR (2021) Secure and efficient data transmission for wireless sensor networks by using optimized leach protocol. ICICT 2021:50-55.
- Sai NR, Cherukuri T, (2021) Encrypted negative password identification exploitation RSA Rule. ICICT 6: 1-4.
- Vijaya N, Arifuzzaman SM, Raghavendra S, Manikya R (2020) Analysisof arrhenius activation energy in electrically conducting casson fluidflow induced due to permeable elongated sheet with chemical reaction and viscous dissipation. FHMT 15: 15 - 26.
- Kumar JS, Devi PR, Sai NR, Kumar SS ,T. Benarji et al(2021) Battling fake news: A survey on mitigation techniques and identification. ICOEI 17: 829-835.
- Raghavendra SN, Bhargav J, Aneesh M, Vinay S, Nikhil et al.(2021) Discovering network intrusion using machine learning and data analytics approach. ICICV 22: 118-123.
- A. Pavan Kumar, Lingam Gajjela, Raghavendra SN(2020) A hybrid hash-stego for secured message transmission using stegnography. Mater Sci Eng C 981:1-11.
- Smitha C, Gayathri E, N. Raghavendra S, Jogendra KM (2020) Analogous approach towards performance analysis for software defect prediction and prioritization. Mater Sci Eng C 981:1-12.
- Gayathri E, Smitha C, Jogendra KM, Raghavendra S (2020) Hybrid learning method to detect the malicious transactions in network data. Mater Sci Eng C 981:1-10.
- Raghavendra SN (2020) An efficient high energy based routing protocol for wireless sensornetworks. Test Eng Manag 83:18069-18075.
- Raghavendra SN (2020) Analysis of artificial neural networks based intrusion detection system. Int J Adv Sci Technol 8:1-9.


 ) Bayes Net; (
) Bayes Net; (  ) NaiveBayes; (
) NaiveBayes; (  ) J48;
(
) J48;
(  ) J48 Graft; (
) J48 Graft; (  ) random Forest
) random Forest